LeetCodeCampsDay30贪心part04
LeetCodeCampsDay30贪心part04
三个区间问题的题目,用贪心算法解决
本题需要用到python的lambda表示式
x.sort(key = lambda x: (x[0], x[1]))
表示对列表x进行排序,优先对x[0]从小到大排序,再按x[1]从小到大
如果需要先从大到小,再从小到大,可以先使用-x[0]
x.sort(key = lambda x: (-x[0], x[1]))
452. 用最少数量的箭引爆气球
https://leetcode.cn/problems/minimum-number-of-arrows-to-burst-balloons/
有一些球形气球贴在一堵用 XY 平面表示的墙面上。墙面上的气球记录在整数数组 points ,其中points[i] = [xstart, xend] 表示水平直径在 xstart 和 xend之间的气球。你不知道气球的确切 y 坐标。
一支弓箭可以沿着 x 轴从不同点 完全垂直 地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 x``start,x``end, 且满足 xstart ≤ x ≤ x``end,则该气球会被 引爆 。可以射出的弓箭的数量 没有限制 。 弓箭一旦被射出之后,可以无限地前进。
给你一个数组 points ,返回引爆所有气球所必须射出的 最小 弓箭数 。
示例 1:
1 | 输入:points = [[10,16],[2,8],[1,6],[7,12]] |
示例 2:
1 | 输入:points = [[1,2],[3,4],[5,6],[7,8]] |
示例 3:
1 | 输入:points = [[1,2],[2,3],[3,4],[4,5]] |
提示:
1 <= points.length <= 105points[i].length == 2-231 <= xstart < xend <= 231 - 1
贪心思路
本题的最小结果,其实是“最多的重合区间个数”
- 对于区间问题,我们先对区间的左端点进行排序(从小到大),如果左端点一样,再按右端点大小到大排序
- 随后,再按重复的区间进行讨论(只有两种情况,排序的结果会保证这一点)
- 当前区间i左边界大于上一区间(i-1)右边界,即:两个区间无重合,则说明上一个区间i-1需要一个箭
- 当前区间i左边界小于等于上一区间i-1右边界,两个区间重合,此时,可以用一个箭射穿两个区间;并且需要更新这两个区间的右边界,让他俩的右边界变成他俩右边界的最小值
points[i - 1][1] = points[i][1] = min(points[i - 1][1], points[i][1]);这样做的目的,是为了让下一个区间i+1把当前区间i当成"i-1"进行处理,即,当i-1和i重复了,是否能把i+1也带上一起射穿。
贪心代码
- 时间复杂度:O(nlog n),因为有一个快排
- 空间复杂度:O(n),有一个快排,最差情况(倒序)时,需要n次递归调用。因此确实需要O(n)的栈空间
1 | class Solution: |
435. 无重叠区间
https://leetcode.cn/problems/non-overlapping-intervals/
给定一个区间的集合 intervals ,其中 intervals[i] = [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。
注意 只在一点上接触的区间是 不重叠的。例如 [1, 2] 和 [2, 3] 是不重叠的。
示例 1:
1 | 输入: intervals = [[1,2],[2,3],[3,4],[1,3]] |
示例 2:
1 | 输入: intervals = [ [1,2], [1,2], [1,2] ] |
示例 3:
1 | 输入: intervals = [ [1,2], [2,3] ] |
提示:
1 <= intervals.length <= 105intervals[i].length == 2-5 * 104 <= starti < endi <= 5 * 104
贪心思路
本题和上一题的思路很像,以及代码都非常像;本题是不需要处理不重叠区间的情况;
同样需要注意的一点是,将两个重叠区间的右边界,变成两个区间右端点的最小值,相当于融合成了一个区间,从而让下一个区间和这个新的右端点进行比较判断
贪心代码
- 时间复杂度:O(nlog n) ,有一个快排
- 空间复杂度:O(n),有一个快排,最差情况(倒序)时,需要n次递归调用。因此确实需要O(n)的栈空间
1 | class Solution: |
763. 划分字母区间
https://leetcode.cn/problems/partition-labels/
给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。例如,字符串 "ababcc" 能够被分为 ["abab", "cc"],但类似 ["aba", "bcc"] 或 ["ab", "ab", "cc"] 的划分是非法的。
注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s 。
返回一个表示每个字符串片段的长度的列表。
示例 1:
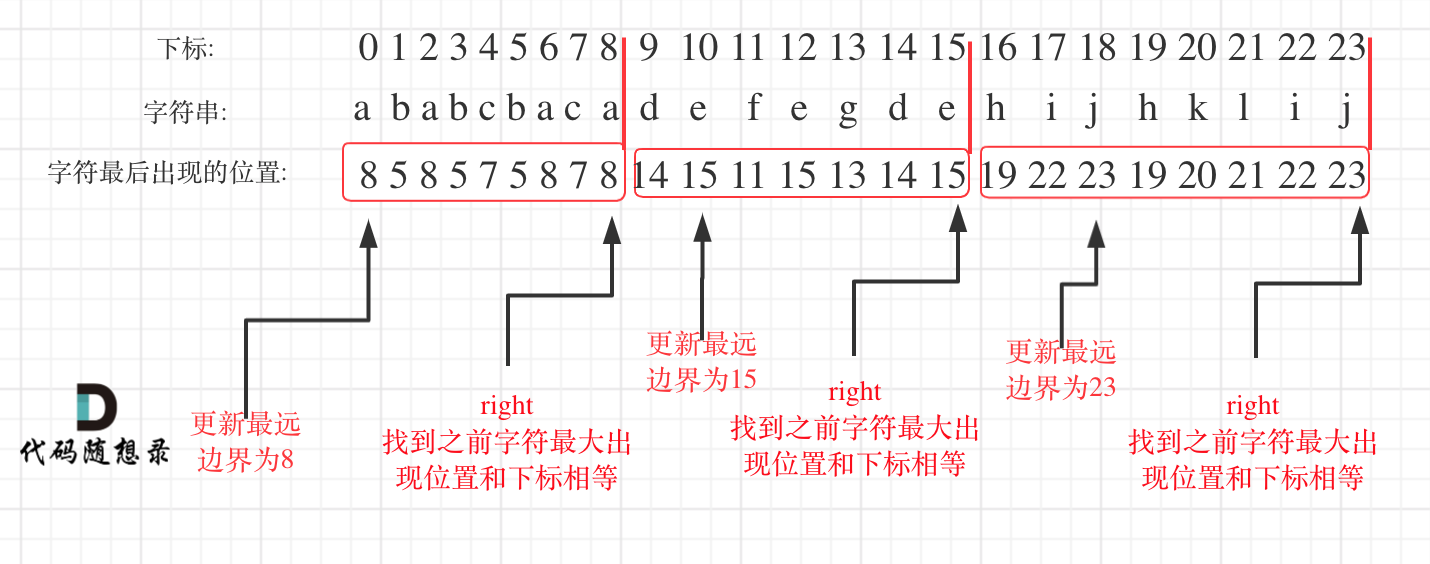
1 | 输入:s = "ababcbacadefegdehijhklij" |
示例 2:
1 | 输入:s = "eccbbbbdec" |
提示:
1 <= s.length <= 500s仅由小写英文字母组成
贪心思路
思路一:
同一字母最多出现在一个片段中,也暗示这是个区间问题和前面两个题目一样
可以对每个字母看成一个区间(最多有26个区间),记录每个字母的首、末区间位置;然后进行排序,再统计最大重合区间,区间有重合的就合并(按最大右端点合并),并统计合并后区间长度;如果不重叠,则边界就是答案
将区间按左边界从小到大排序,找到边界将区间划分成组,互不重叠。找到的边界就是答案。
思路二:
思路2更灵活,对每个字母来说,使用hashtable,记录每个字母出现的最远位置的下标;(第一次遍历)
再遍历一次,不过这次使用个变量farest,记录当前hashtable里,最远位置的下标,当farest==i时,(比如i=8=farest),此时就达到了一个最长区间。
贪心代码
思路一
- 时间复杂度:O(n)
- 空间复杂度:O(1),使用的hash数组是固定大小
1 | class Solution: |
思路二代码
1 | class Solution: |







