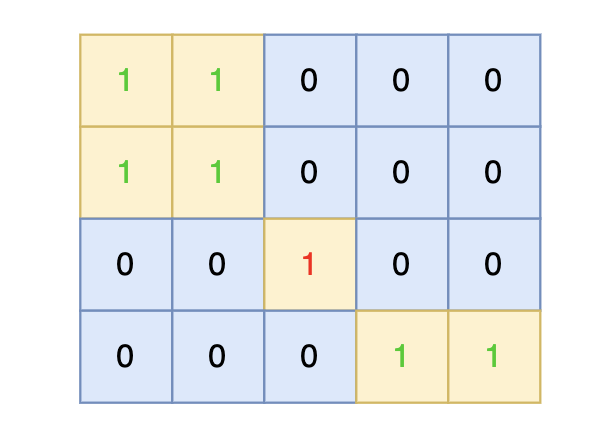
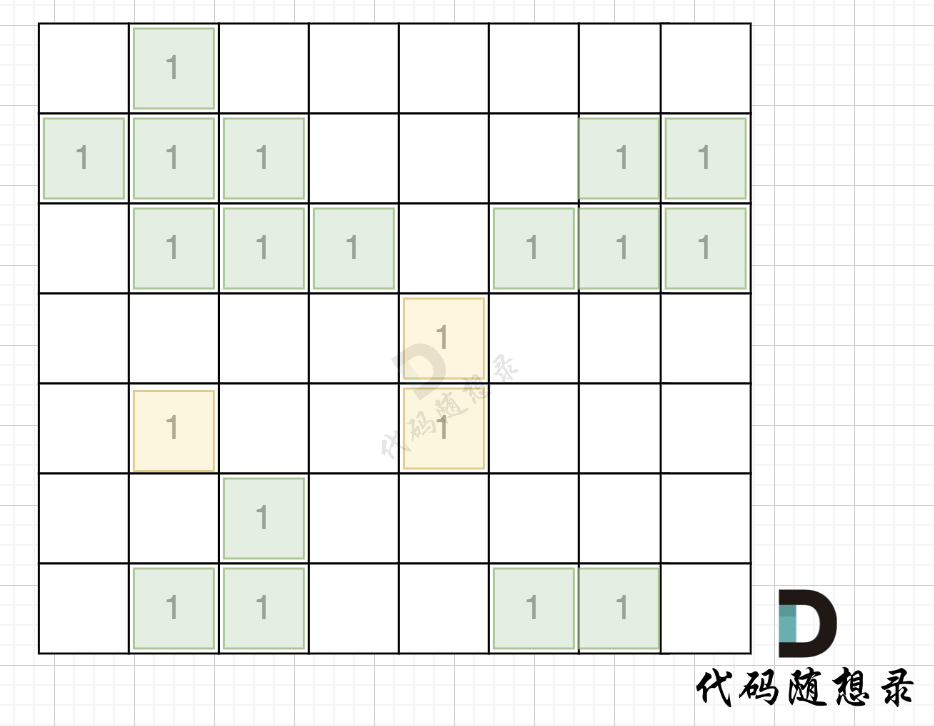
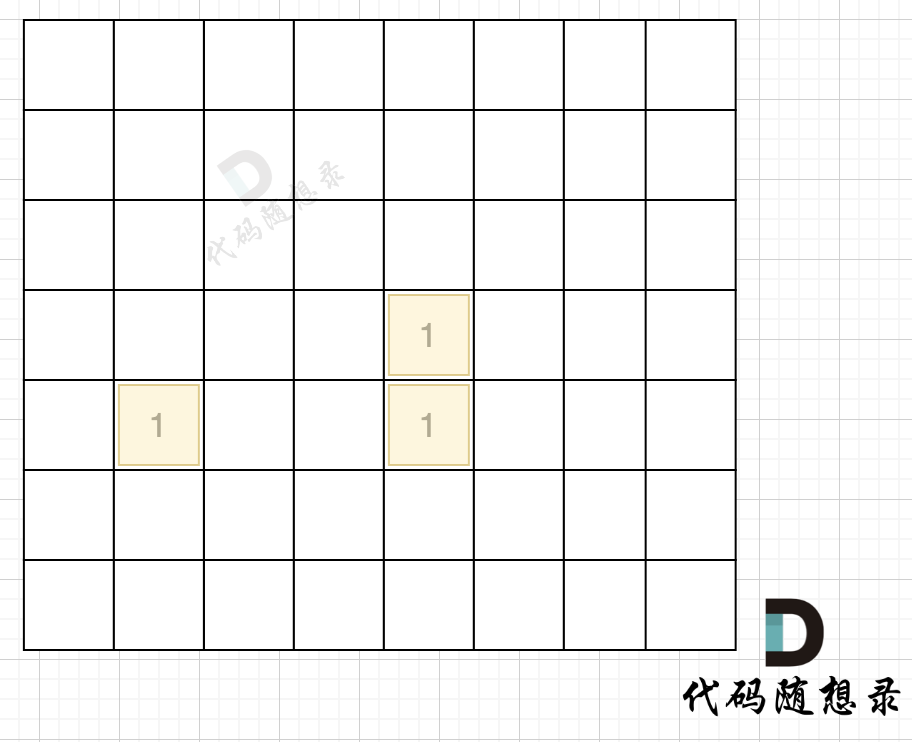
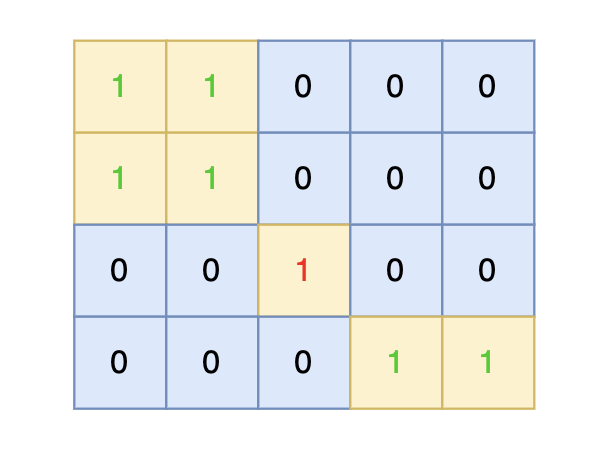
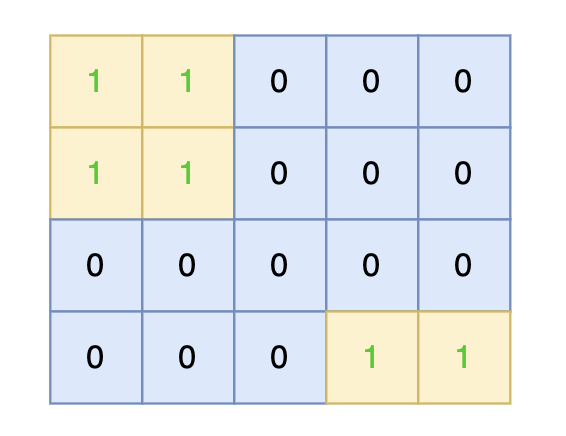
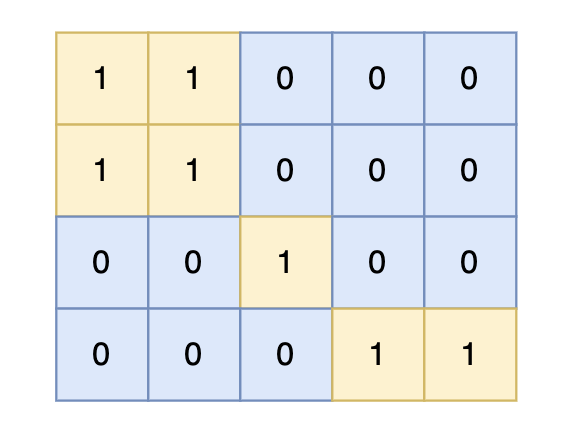
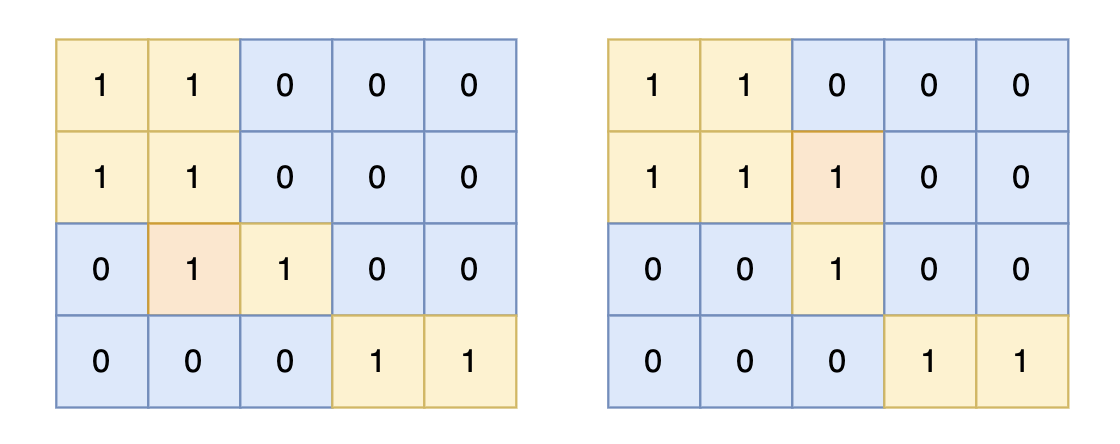
direction = [[0, 1], [1, 0], [-1, 0], [0, -1]] # from collections import deque
# 将x,y相邻的位置都变成海洋(0) defbfs(graph, x, y): que = deque() que.append([x, y])
while que: curX, curY = que.popleft() graph[curX][curY] = 0 for i, j in direction: nextX = curX + i nextY = curY + j if nextX < 0or nextY < 0or nextX >= len(graph) or nextY >= len(graph[0]): continue
if graph[nextX][nextY] == 1: que.append([nextX, nextY])
defmain(): n, m = map(int, input().split()) graph = list() for _ inrange(n): graph.append(list(map(int, input().split()))) res = 0 # 从上、下开始将相邻格子变成海洋 for i inrange(m): if graph[0][i] == 1: bfs(graph, 0, i) if graph[n - 1][i] == 1: bfs(graph, n - 1, i) # 从左、右开始将相邻格子变成海洋 for i inrange(n): if graph[i][0] == 1: bfs(graph, i, 0) if graph[i][m - 1] == 1: bfs(graph, i, m - 1)
for i inrange(1, n - 1): for j inrange(1, m - 1): if graph[i][j] == 1: res += 1
area = 1 flag = 0 while que: curX, curY = que.popleft() for i, j in direction: nextX = curX + i nextY = curY + j if nextX < 0or nextY < 0or nextX >= len(graph) or nextY >= len(graph[0]): continue
if graph[nextX][nextY] == 1and visited[nextX][nextY] == 2: flag = 1
if graph[nextX][nextY] == 1and visited[nextX][nextY] == 0: if nextX == 0or nextY == 0or nextX == len(graph) - 1or nextY == len(graph[0]) - 1: visited[nextX][nextY] = 2 flag = 1 else: visited[nextX][nextY] = 1 area += 1 que.append([nextX, nextY]) if flag == 1: return -1 return area
defmain(): n, m = map(int, input().split()) graph = list() for _ inrange(n): graph.append(list(map(int, input().split()))) res = 0 visited = [[0] * m for _ inrange(n)] for i inrange(1, n - 1): for j inrange(1, m - 1): if visited[i][j] == 0and graph[i][j] == 1: visited[i][j] = 1 res += max(bfs(graph, visited, i, j), 0)
defbfs(graph, x, y): from collections import deque que = deque() que.append([x, y])
while que: curx, cury = que.popleft() # 设置为2表示可以被保留 graph[curx][cury] = -1 for i, j in direction: nextx = curx + i nexty = cury + j if nextx < 0or nexty < 0or nextx >= len(graph) or nexty >= len(graph[0]): continue if graph[nextx][nexty] == 1: que.append([nextx, nexty])
defmain(): n, m = map(int, input().split()) graph = list() for i inrange(n): graph.append(list(map(int, input().split()))) # 从上、下两行开始 for i inrange(m): if graph[0][i] == 1: bfs(graph, 0, i) if graph[n - 1][i] == 1: bfs(graph, n - 1, i) # 从左、右两列开始 for i inrange(n): if graph[i][0] == 1: bfs(graph, i, 0) if graph[i][m - 1] == 1: bfs(graph, i, m - 1) for i inrange(n): for j inrange(m): if graph[i][j] == 1: graph[i][j] = 0 if graph[i][j] == -1: graph[i][j] = 1 for line in graph: for i in line: print(i, end=" ") print("") if __name__ == "__main__": main()
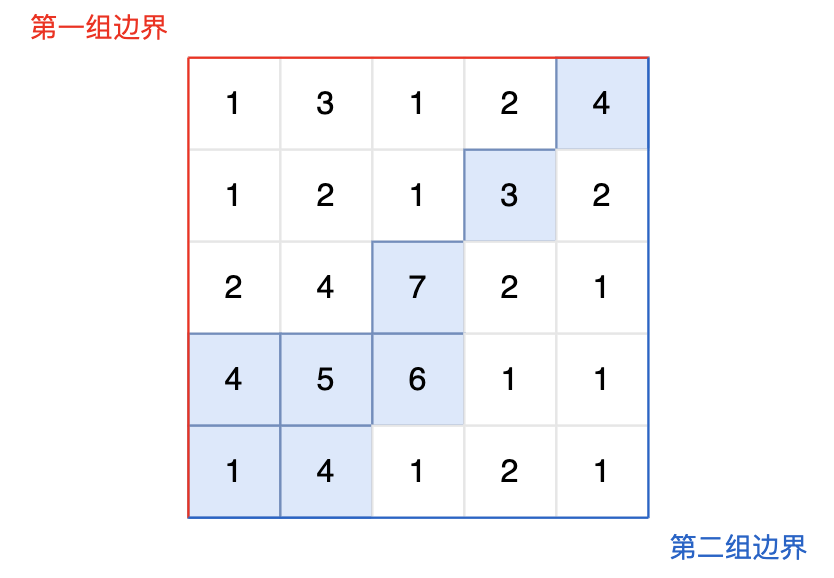
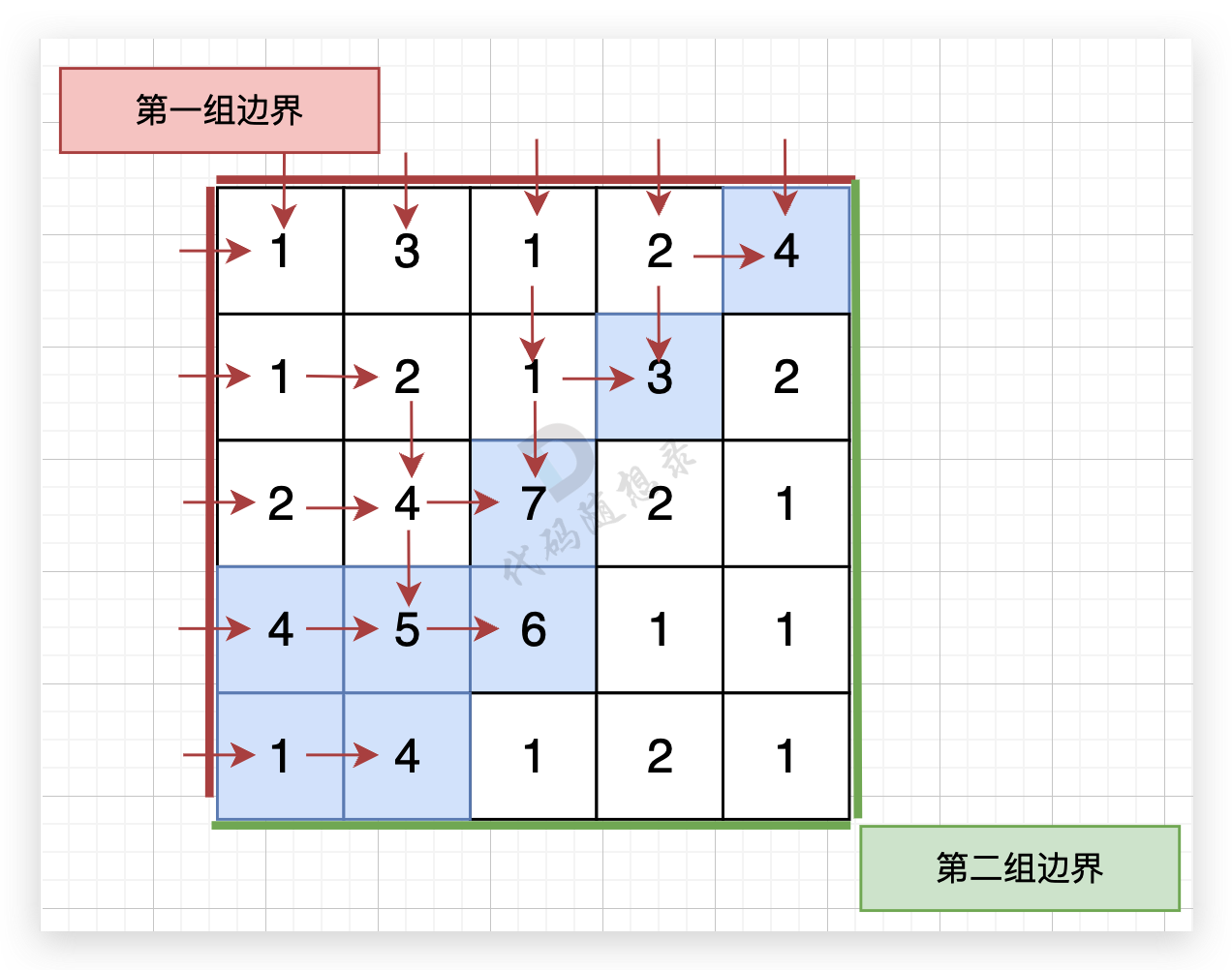
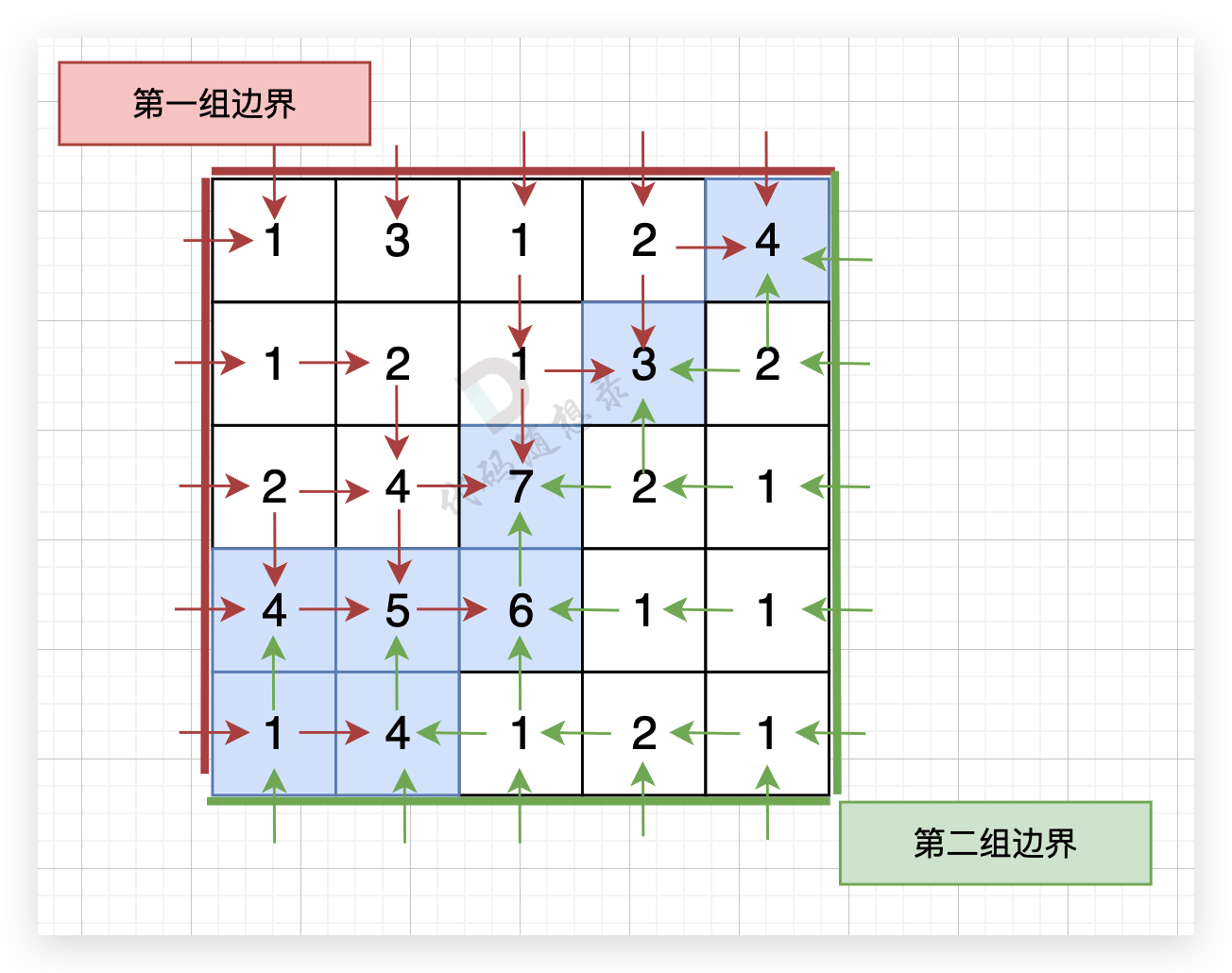
graph = list() for _ inrange(n): graph.append(list(map(int, input().split()))) visited = [[0] * m for _ inrange(n)] for i inrange(n): # 从第一边界(第一列)和从第一边界(第一行)出发 dfs(graph, visited, firstborder, i, 0) for i inrange(m): dfs(graph, visited, firstborder, 0, i) visited = [[0] * m for _ inrange(n)] for i inrange(n): # 第二边界(最后一列)和第二边界(最后一行)出发 dfs(graph, visited, secondborder, i, m - 1) for i inrange(m): dfs(graph, visited, secondborder, n - 1, i)
res = firstborder & secondborder # 最后统计同时出现在firstborder和secondborder里的
for x, y in res: print(f"{x}{y}")
if __name__ == "__main__": main()
广度优先思路
只有写法和深度优先不太一样,注意将visited的判断放在while循环内
广度优先代码
那么本题整体的时间复杂度其实是: 2 * n * m + n * m ,所以最终时间复杂度为 O(n * m) 。
defbfs(graph, visited, border, x, y): from collections import deque que = deque() que.append([x, y])
while que: curx, cury = que.popleft() if visited[curx][cury] == 1: continue visited[curx][cury] = 1 border.add((curx, cury))
for i, j in direction: nextx = curx + i nexty = cury + j if0 <= nextx < len(graph) and0 <= nexty < len(graph[0]) andint(graph[curx][cury]) <= int(graph[nextx][nexty]): que.append([nextx, nexty])
defmain(): global firstborder, secondborder
n, m = map(int, input().split())
graph = list() for _ inrange(n): graph.append(list(map(int, input().split()))) visited = [[0] * m for _ inrange(n)] for i inrange(n): # 从第一边界(第一列)和从第一边界(第一行)出发 bfs(graph, visited, firstborder, i, 0) for i inrange(m): bfs(graph, visited, firstborder, 0, i) visited = [[0] * m for _ inrange(n)] for i inrange(n): # 第二边界(最后一列)和第二边界(最后一行)出发 bfs(graph, visited, secondborder, i, m - 1) for i inrange(m): bfs(graph, visited, secondborder, n - 1, i)
res = firstborder & secondborder # 最后统计同时出现在firstborder和secondborder里的
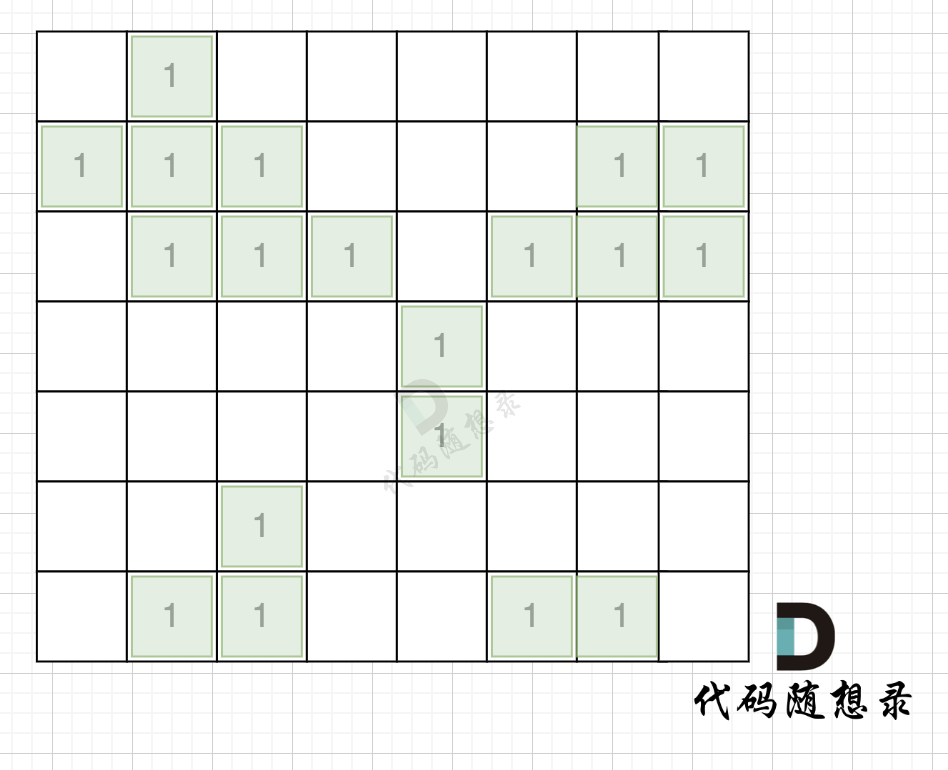
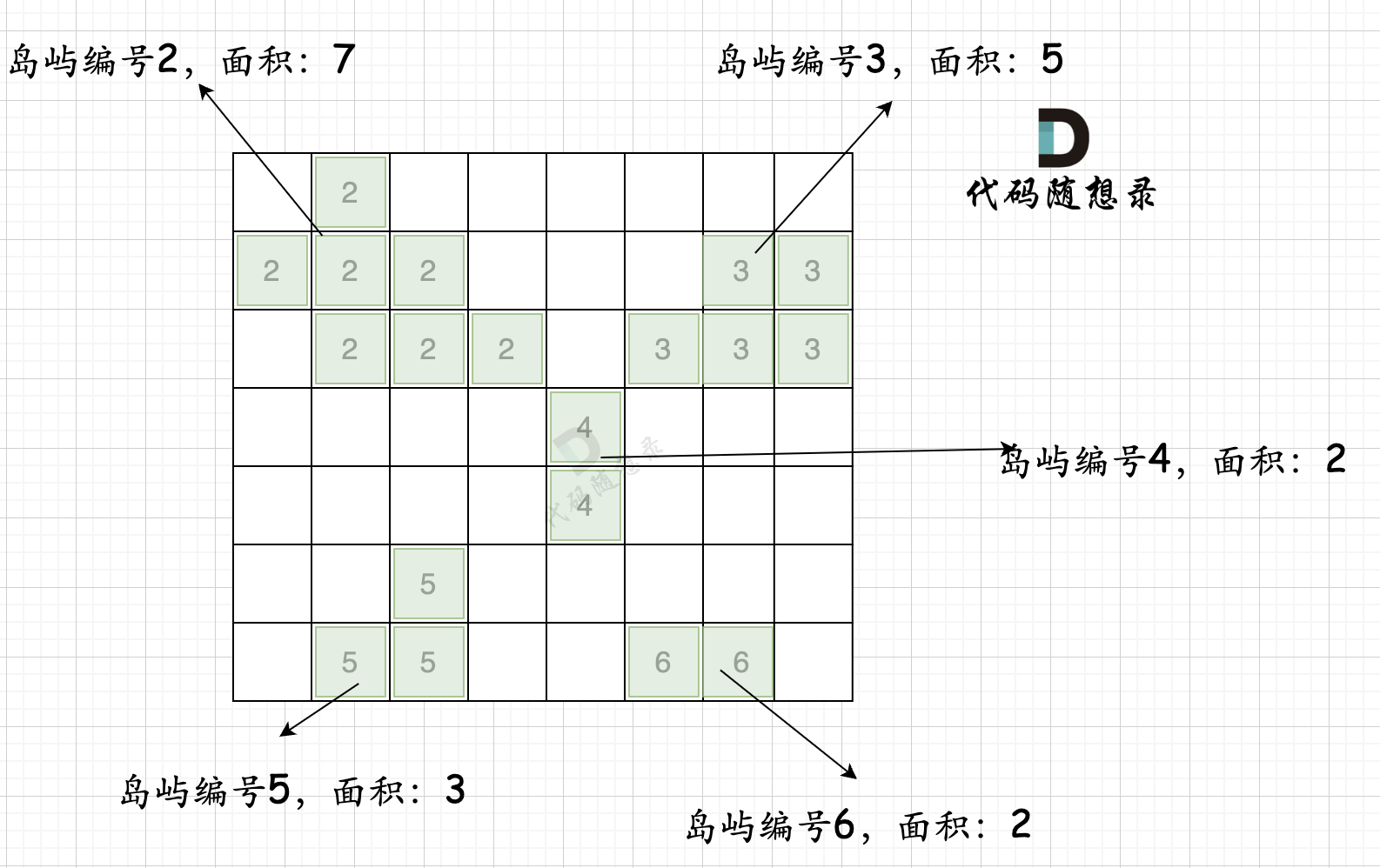
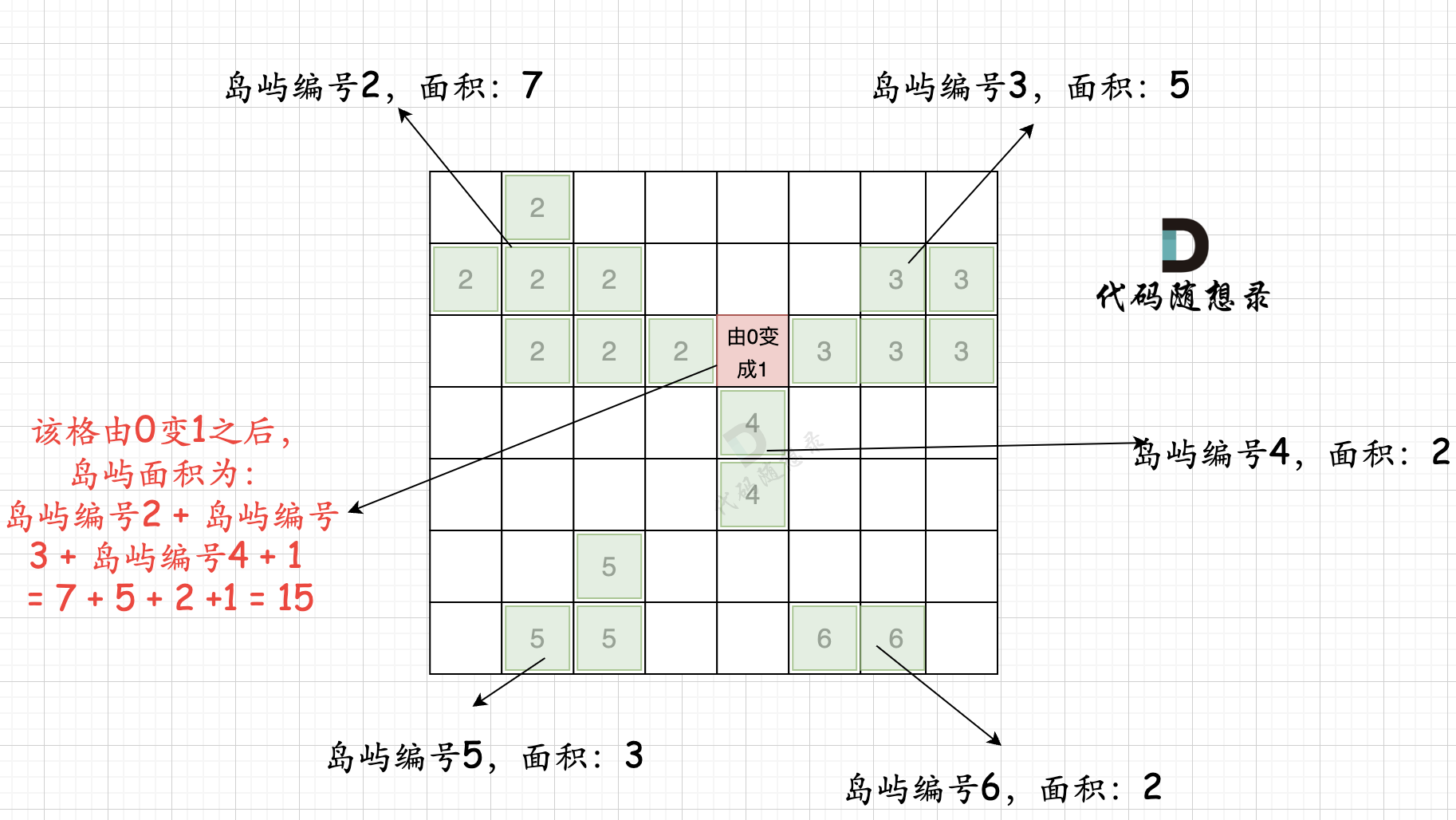
# bfs的目的是计算每个岛屿的面积,以及将岛屿“涂色”,同一个岛屿将拥有相同的编号 defbfs(graph, visited, x, y, number) -> int: from collections import deque
area = 1 que = deque() que.append([x, y])
while que: curx, cury = que.popleft() # 进行岛屿编号 graph[curx][cury] = number for i, j in direction: nextx = curx + i nexty = cury + j if0<= nextx < len(graph) and0<= nexty < len(graph[0]) and visited[nextx][nexty] == 0and graph[nextx][nexty] == 1: # 注意计算面积的位置 visited[nextx][nexty] = 1 area += 1 que.append([nextx, nexty]) return area
defmain(): n, m = map(int, input().split())
graph = list()
for _ inrange(n): graph.append(list(map(int, input().split()))) number = 1 # res为最大岛屿面积 res = 0 table = dict() visited = [[0] * (m) for _ inrange(n)] # 第一次遍历,将岛屿编号并且记录最大面积 for i inrange(n): for j inrange(m): if graph[i][j] != 0and visited[i][j] == 0: number += 1 temp = bfs(graph, visited, i, j, number) res = max(res, temp) table[number] = temp # 第二次遍历,只针对海洋进行操作 # 对海洋块的周围岛屿进行计算,注意某一个海洋块,有可能被同一个编号的岛屿包围,所以不要重复添加某个岛屿 for x inrange(n): for y inrange(m): # 如果为海洋 if graph[x][y] == 0: temp = 1 # 记录是否已经添加过某个岛屿 added = set() for i, j in direction: nextx = x + i nexty = y + j if0<= nextx < len(graph) and0<= nexty < len(graph[0]) and graph[nextx][nexty] != 0: if graph[nextx][nexty] notin added: temp += table[graph[nextx][nexty]] added.add(graph[nextx][nexty]) # 求岛屿最大面积 res = max(temp, res)